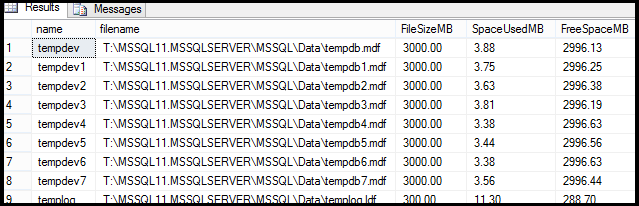
One of the Microsoft’s recommendation for optimizing the tempDB performance is to make each tempdb data file the same size.
Today, on one of our servers, I noticed there are 13 data files with different sizes as shown in the below screenshot:

My target here is to configure tempdb with 8 equi sized data files and one log file. So, in this case I have to delete those 5 extra data files and re-size the remaining 8 files equally.
To achieve this I followed the below simple three step process (The same procedure can be applied to any user databases as well)
-- Step1: First empty the data file
USE tempdb
GO
DBCC SHRINKFILE (tempdev12, EMPTYFILE); -- to empty "tempdev12" data file
GO
Data file won’t gets deleted unless it is empty. So before going to Step2 to delete the data file, we should first empty the data file which can be done from the Step1 above.
Note: If encountered this error Msg 2555, Level 16, State 1, Line 1 while performing the above operation, please refer to this post –> Msg 2555, Level 16, State 1, Line 1 – Error DBCC SHRINKFILE with EMPTYFILE option
--Step2: Remove that extra data file from the database
ALTER DATABASE tempdb
REMOVE FILE tempdev12; --to delete "tempdev12" data file
GO
I repeated the above two steps to delete the other files as well. Below is the screenshot after deleting the extra files

--Step3: Re-size the data files to target file size
-- Use ALTER DATABASE if the target file size is greater than the current file size
USE [master]
GO
ALTER DATABASE [tempdb]
MODIFY FILE ( NAME = N'tempdev', SIZE = 3072000KB ) --grow to 3000 MB
GO
--Use DBCC SHRINKFILE if the target file size is less than the current file size
USE [tempdb]
GO
DBCC SHRINKFILE (N'tempdev' , 3000) --shrink to 3000 MB
GO
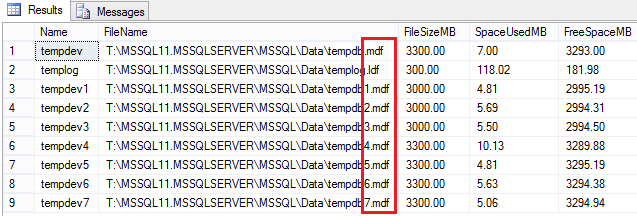
In my case, the target file size is 3000 MB which is greater than the current file size, so I ran the ALTER DATABASE command for all the 8 files. And below is the screenshot after re-sizing the files

Note: The same procedure can be used for removing extra log files as well. Make sure the log file you are trying to empty do not have any active portion of the log. Run DBCC LOGINFO on your specified database, taking note of the FileId and the Status indicator (2 showing that it is an active VLF)
Read Full Post »